Your Git History is a Disgusting Overcooked Diff Soup
Who remembers SourceForge? I do.
That was a time when every open source project worked more or less like Linux still does. You’d find a project on SourceForge, download a tarball, make changes, and then email a patch to a mailing list, or even worse, post it in a forum thread.
One nice thing about that era was that a patch was usually a single commit, and it had to be properly described. It could easily become detached from the original email or forum post, so you made it as clear and as atomic as possible. The goal was simple: help the reviewer understand both the intent and what the code actually does.
Then you had to wait. Maybe someone would notice your patch. Maybe it would apply cleanly. Maybe someone would care enough to reply.
Github completely changed this ritual.
- Fork the repo.
- Make your changes.
- Open a pull request.
Suddenly, you don't need to understand mailing list etiquette. You don’t need to learn how to manually craft patches. And both you and the maintainer can call each other f-words in public.
GitHub changed the behavior of millions of developers and introduced a bunch of tools that make reviewing third-party code easier.
So the problem is solved?
GitHub optimized for ease of contribution and incremental review. What it didn't optimize for is the quality of history.
A typical PR today looks like this:
feat: add payment API
fix: address review comments
fix: rename variable
fix: lint
fix: actually fix test
oops
final fix
fix: lintFrom a reviewer's perspective, this works great. They look at the latest changes, and the feedback loop is fast.
But look at your git log or GitHub commit history. It’s useless. Unreadable.
"Surely this isn't true for large, popular open source projects," you might say.
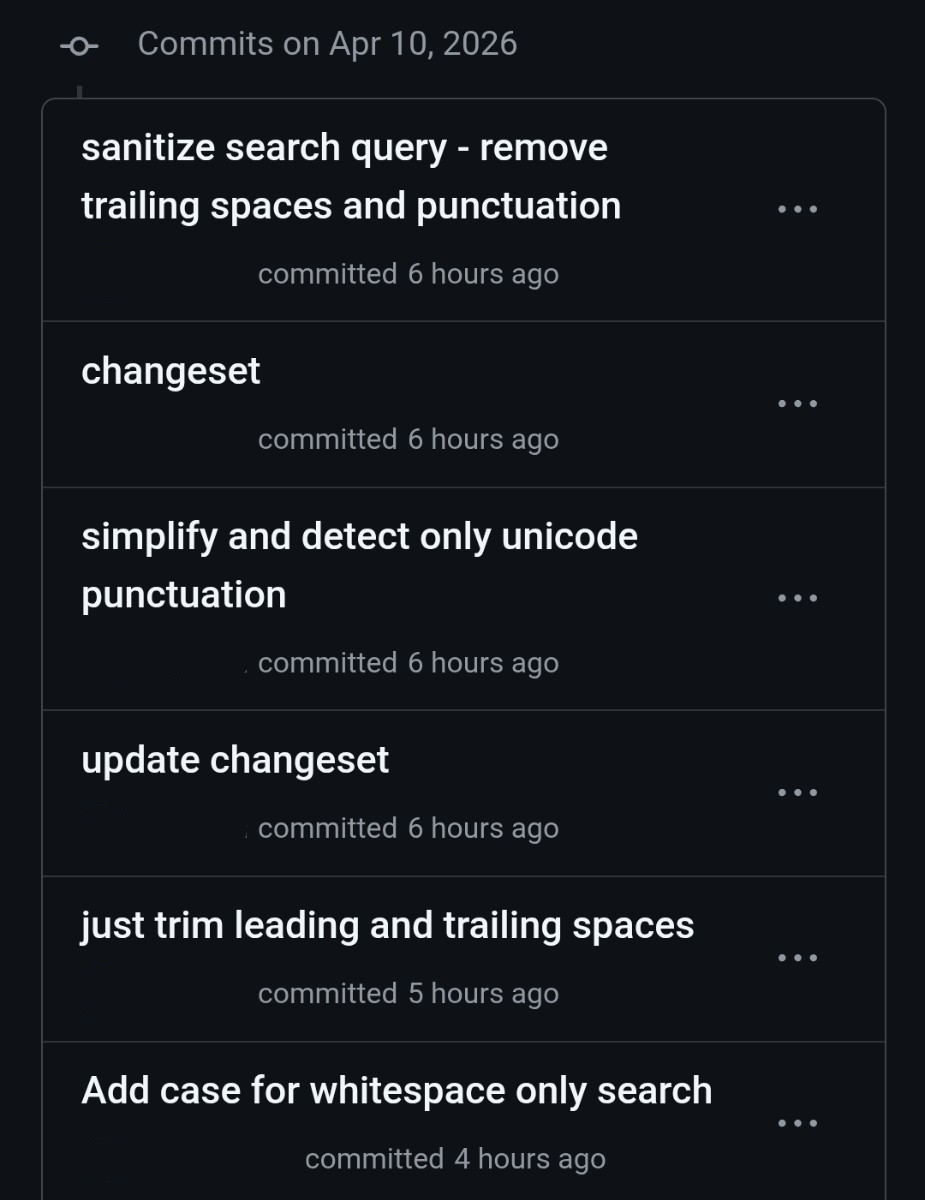
Wrong.
Take any popular repo. Maintainer PR. Same slop commits. This is just the default GitHub workflow playing out:
- Author opens a PR with an initial idea
- Review starts
- Feedback arrives
- Changes are pushed incrementally
- Repeat until approval
Each step makes sense locally. The reviewer sees small diffs, and the author moves quickly.
But to someone reading the history later, the result is a mess: no clear separation of concerns, overlapping attempts at the same idea, mechanical changes mixed with semantic ones, and commits from debugging sessions. Once merged, that history becomes permanent.
"But what about squashing and merging?" you might ask.
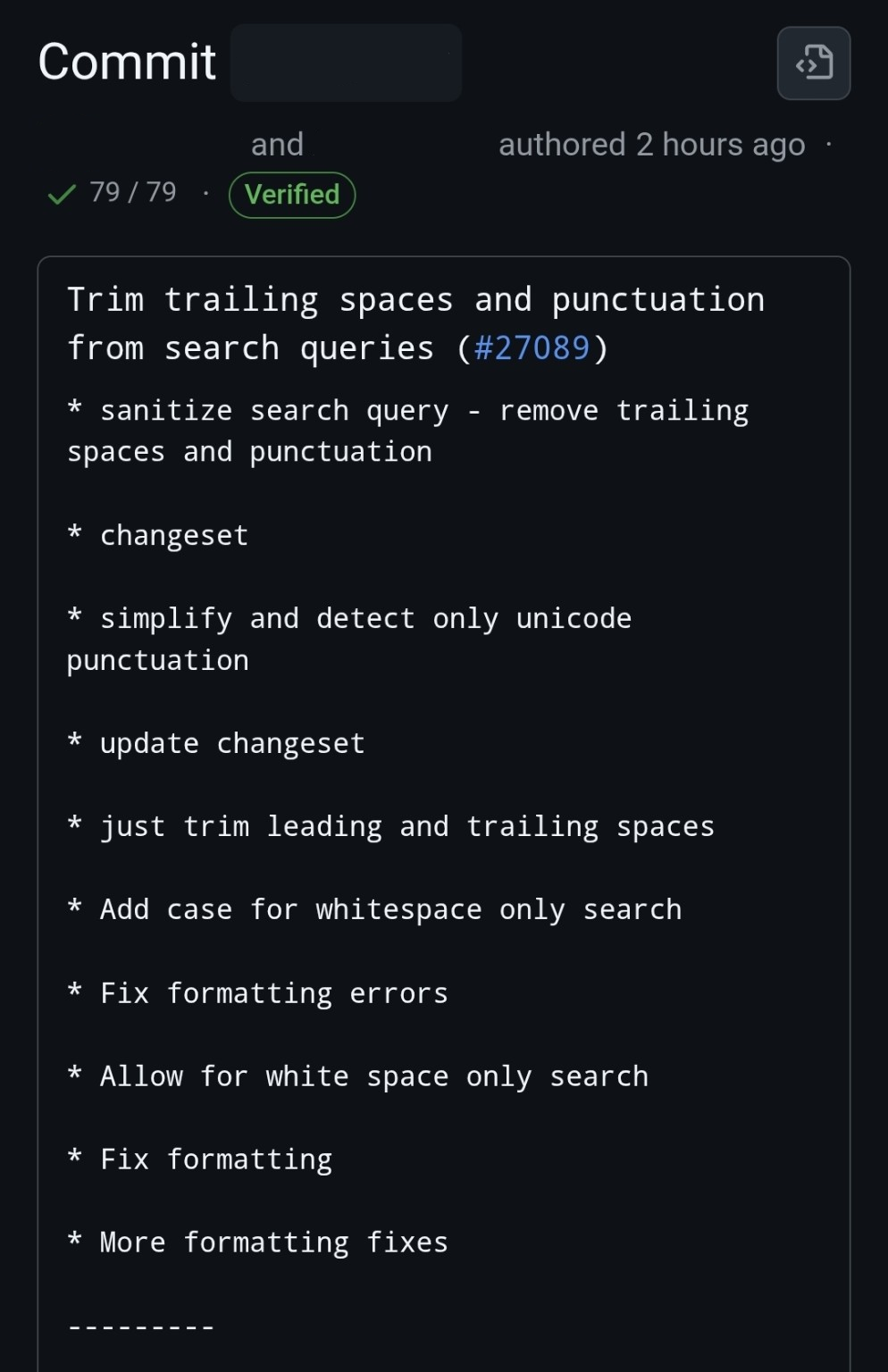
Well… kinda, it reduces the number of messy commits in the repo’s history.
But do you actually understand what that single commit does? Can you infer the author's intent?
Let's check the PR description.
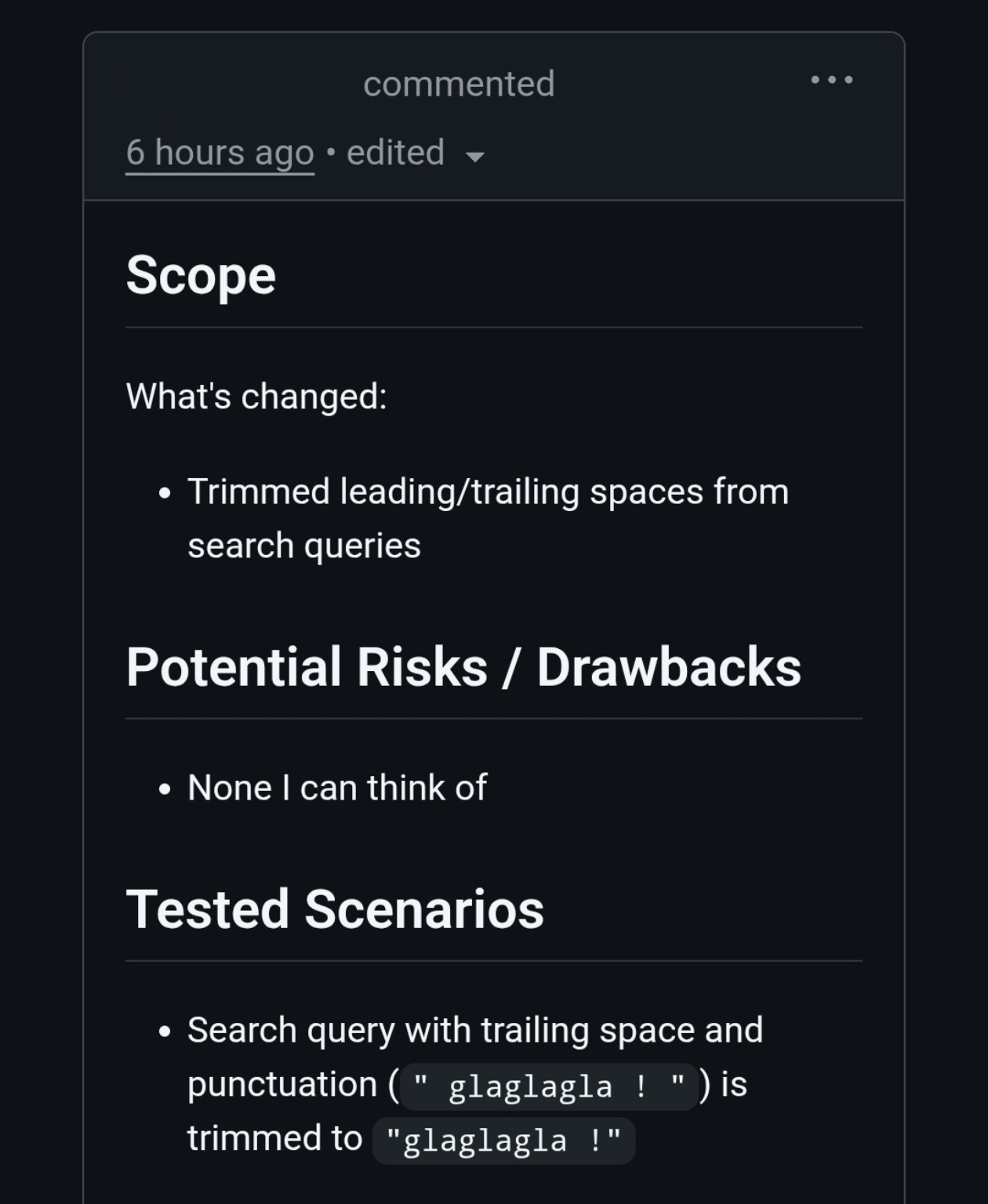
A crude description that explains nothing.
Great.
Maybe there is a linked issue?
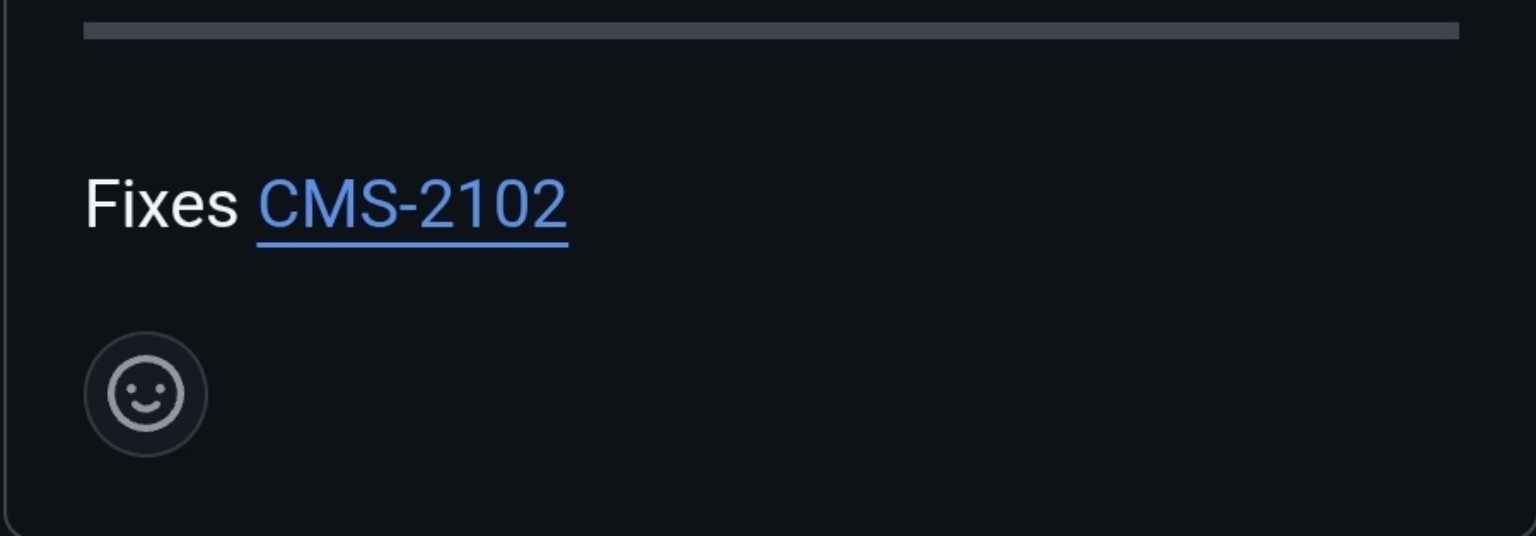
There is, but it points to a private Linear board.
So now:
- the commits are useless
- the PR description is useless
- and even the issue link is useless
To be clear, this is a popular, profitable open source project with 40k stars.
And I’m not claiming I’m some perfect example of atomic commits. I also fall into the trap of messy commits and weak PR descriptions.
But I think this is a direct consequence of GitHub abstracting away commits and centering everything around PRs.
Older workflows were painful, but they treated changes differently. You didn't send "fix commits", you sent a new version of the same patch.
v1 became v2, v2 became v3. Each version refined the same logical units. Patch 1 stayed patch 1. Patch 2 stayed patch 2. Reviewers didn't reread everything, they looked at what changed between versions.
Commits should represent stable, logical units, even as they evolve.
For example:
1. refactor payment logic
2. introduce new API
3. migrate callersThese are clean, logical steps.
Now review comes in with feedback. Instead of adding new commits, you refine the originals:
1. refactor payment logic (improved)
2. introduce new API (fixed edge cases)
3. migrate callers (cleaner)The structure stays the same. The intent stays clear.
Now the reviewer doesn't need to reread everything from scratch, they can focus on what changed between iterations.
Unfortunately, this style of review is hard to achieve with today's popular tools. You might not be able to go full Gerrit, but you can still improve your workflow.
Each commit should have a clear purpose. Commit messages should reflect intent.
Why does this matter? Because eventually, someone will ask:
- Why does the system behave this way?
- Was this change intentional?
- What introduced this bug?
- Can we safely revert part of this?
And they will rely on commit history to answer those questions. So will your tools. git blame, git bisect, and rebasing all work much better when commits are atomic and each one does one thing well. --first-parent on merge commits does not really solve this, it just works around the problem by treating merges as opaque blocks. Inside those blocks, you can still have intermediate commits that do not build or do not represent coherent states. Good luck bisecting that. If your history is messy, the usual solution is just to slap another commit on top and hope it fixes the issue.
We invest heavily in designing code. We think about abstractions, architecture, and API contracts all the time. But commit history, the record of those decisions, is often treated as trash.
A good history explains intent, supports debugging, and enables safe change. The repository you leave behind is much more than just the code in main. It's also the path that got it there, and that path deserves the same level of care as the code itself.
Thank you, @traits_reality, for taking the time to review the article and for your thoughtful feedback. I really appreciate it.